
Python: Menggunakan concat Function untuk Join Dataframe
Kadang kala jumlah columns tidak sama


Baru-baru ini ada satu requirement yang memerlukan saya untuk memasukkan data dalam ke dalam RDS database menggunakan AWS Lambda function.
Satu isu yang saya hadapi adalah data yang dipulangkan oleh S3 bucket adalah json file yang tidak mempunyai struktur yang sama untuk setiap data. Ini menyukarkan untuk saya insert dalam table kerana table mempunyai jumlah column yang tetap.
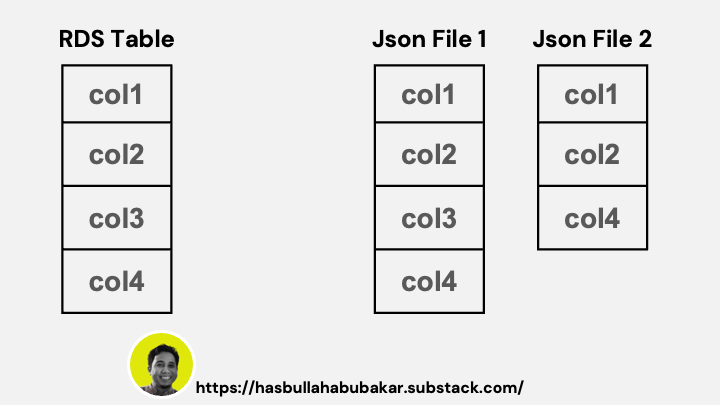
Salah satu cara untuk menyelesaikan masalah ini adalah dengan menggunakan Panda Concat function.
import pandas as pd
# Create an empty DataFrame with only column names
empty_df = pd.DataFrame(columns=['col1', 'col2', 'col3', 'col4'])
# Create another DataFrame with data
data = {'col1': [11, 12, 13], 'col2': ['AA', 'AB', 'AC'], 'col4': ['AA', 'BB', 'CC']}
df_with_data = pd.DataFrame(data)
data2 = {'col1': [21, 22, 23], 'col2': ['BA', 'BB', 'BC'], 'col3': ['DD', 'EE', 'FF'], 'col4': ['SAYA', 'SUKA', 'PYTHON']}
df_with_data2 = pd.DataFrame(data2)
frames = [empty_df, df_with_data, df_with_data2]
result = pd.concat(frames)
print(result)Dalam kod ini, saya mulakan dengan basic data frame empty_df structure yang sama dengan table column. Kemudian data dicipta dalam dataframe data dan data2. Seperti yang anda lihat kedua-dua dataframe tidak mempunyai jumlah column yang sama.
Menggunakan pd.concat(frames) anda boleh mengabungkan data-data tersebut dalams satu dataframe yang lain. Berikut adalah dataframe yang dihasilkan

Selamat mencuba.